Introduction
While 2023 was dominated by cloud-based models such as chatGPT and Claude, this approach could well change this year. This is due to the rapid progress of open-source models, which are gradually closing the gap with proprietary models. These open-source models make it possible to run models locally, which opens up new perspectives that I will outline in this article.
I’ve already published a general analysis of the advantages and disadvantages of open-source models here, as well as a presentation of the French start-up Mistral (here). This article presents things from a more practical point of view: what elements to take into account when choosing and installing a local model, and how to exploit it afterwards.
1. Identify and choose a local model
The first question is to determine which generative model use cases are relevant to you. You can then choose a model that meets your needs. To do this, you can rely on various performance indicators that are regularly published for all available models.
Here you’ll find a dashboard containing a representative series of performance indicators. This dashboard is updated on a regular basis. Let’s take a closer look.
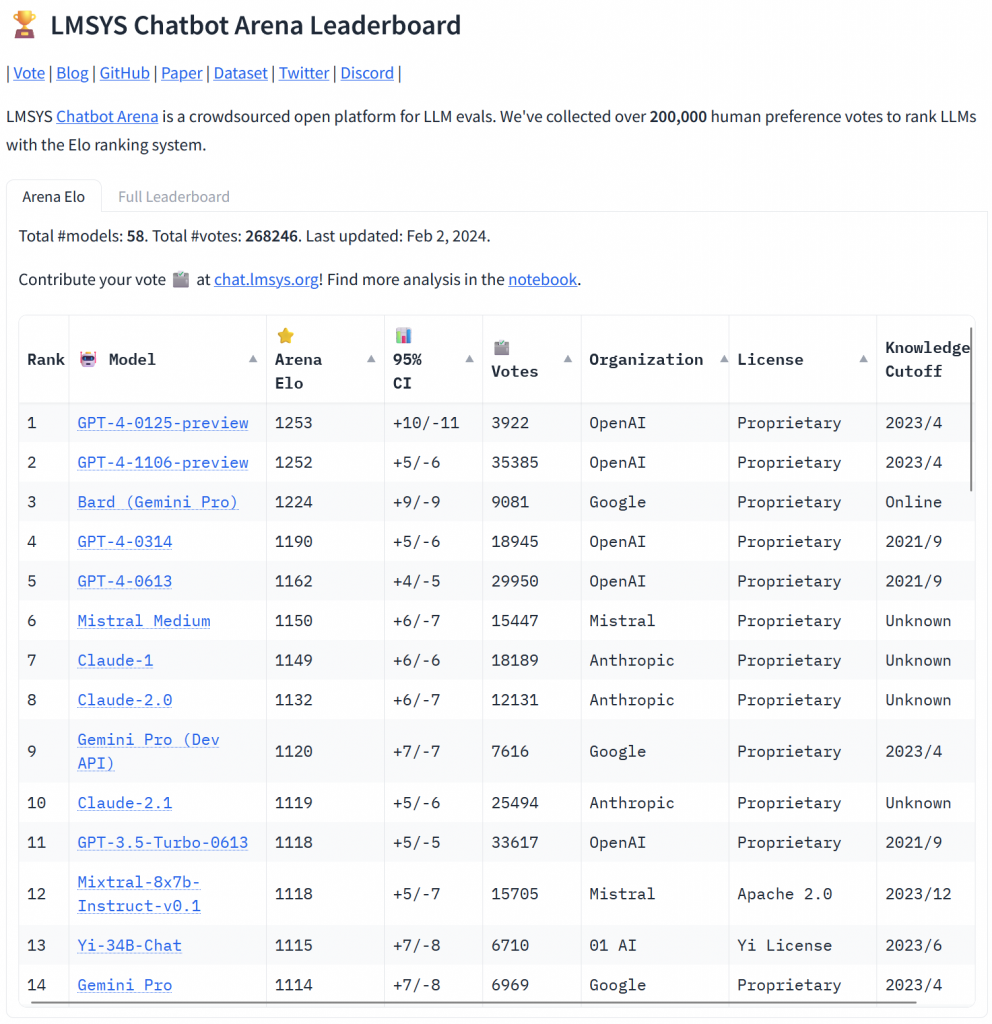
First, let’s take a look at how to interpret the various performance indicators mentioned:
- Arena Elo: This is a rating system comparable to the Elo points used by chess players. A human asks a question and is presented with the answers of two randomly selected models. The human chooses the best answer (the winner), and the Elo points of the two models are updated accordingly. To date, the system has seen more than 200,000 clashes between models…
- MT-bench: This test is based on a series of 80 standardized dialogues covering eight domains (10 questions per domain): writing, role-playing, information retrieval, reasoning, mathematics, programming, natural sciences and humanities. Each dialogue consists of several successive questions on the same topic. Once the dialogue is completed, GPT4 evaluates the quality of the answer and assigns a score.
- MMLU : This indicator uses a large number of multiple-choice questions chosen from 57 categories covering the essentials of human knowledge. The advantage of a multiple-choice question is that evaluation of the answer is immediate and unambiguous.
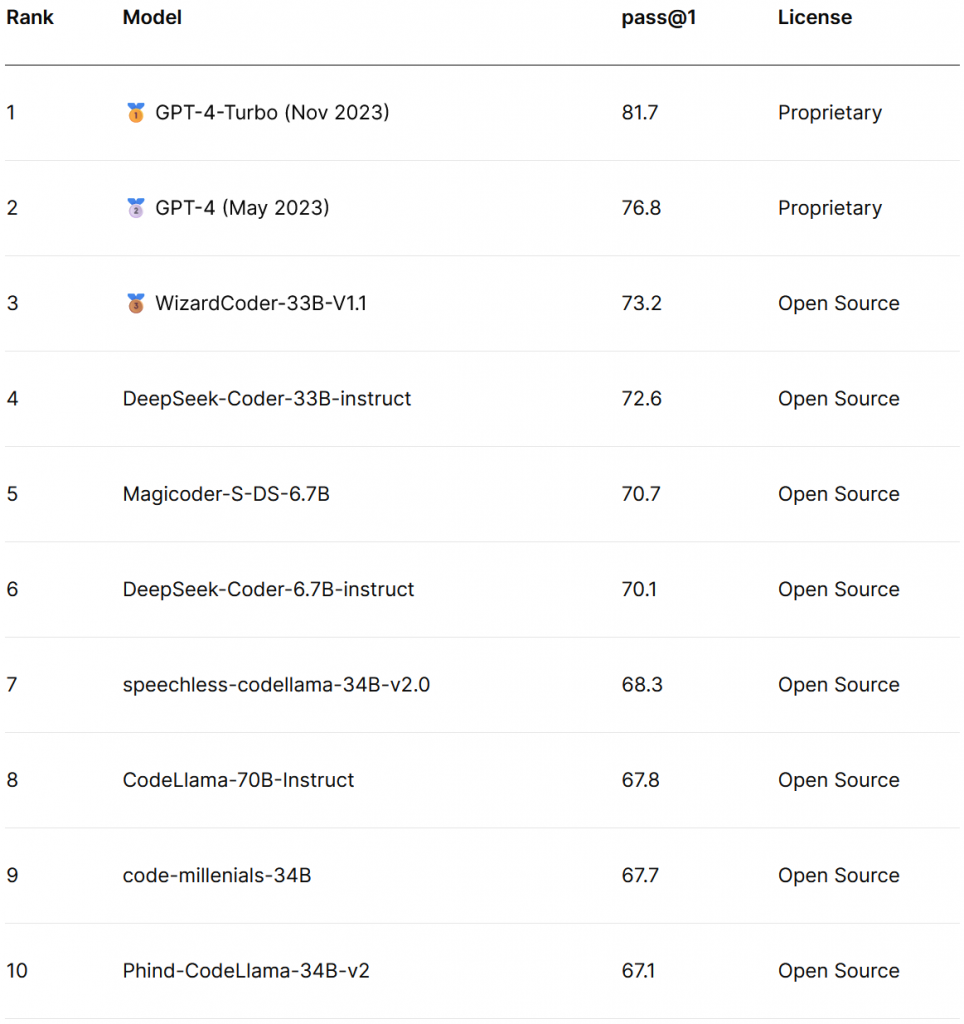
And if programming is your main use case, there’s a specialized HumanEval indicator that evaluates programming aptitude through 164 tests. You can access a dashboard for HumanEval here :
As a general rule, the more parameters a model has, the richer and more precise its responses will be, but the more resources it will require to operate. As many models are available in several sizes, this is a parameter you can play with in a second step if you find that the model is too inaccurate or too resource-hungry. You’ll need to take certain constraints into account: your machine’s memory will limit the size of models that can run on it, while performance will depend above all on the processor(s) available (CPU or GPU).
Another point: some models have been refined to excel in a particular field (artistic creation, programming, the medical field…). If you can get your hands on a model that has been refined in the field you’re interested in, use it as a priority, as it is likely to be relatively more efficient than a general-purpose model of the same size. For example, if you’re interested in programming, go for WizardCoder, Magicoder or CodeLlama…
You can also refine a general open-source model yourself, to bring it as close as possible to your use case. This is a more complex approach, which I’ll cover in a future article.
Finally, always remember to check the license conditions to see if they are compatible with your intended use. Language models are often released under modified open-source licenses containing certain restrictions on use…
2. Install an operating program and download the model
Now’s the time to install an operating engine on your computer. Here are three of them, all free of charge:
You’ll find some good videos explaining how to install and use these programs in the “References” section below. These programs have built-in template search and installation functionality. Manual downloading of the template from a site like HuggingFace is therefore generally not necessary.
Take Ollama, for example, which is extremely easy to use. Once you’ve installed the application on your machine, you can view the list of available templates here :
Then simply request the launch of a model via the ollama run model command. Ollama will first download the model if it is not already present locally, then open an interactive dialog session. Type /bye to stop the interactive session.
Some other commands :
Ollama list: provides a list of locally available models.Ollama pullmodel: installs a model without running it.Ollama rmmodel: deletes the local model.
It couldn’t be simpler…
3. Use a local model
The first and most obvious use case is conversation with the model. The applications described in the previous section offer this functionality without the need for additional installations.
The second use case I’d like to present is the programming assistant integrated into a development environment (IDE). I’ll take as an example one of the most widespread environments: Microsoft VSCode.
There are extensions to VSCode such as Continue and Cody, which provide assistance when interacting with a language model. To interact with a cloud template, you’ll need to configure the desired template and access key. For a local model, all you need to do is specify the application (Ollama or other) and the model to be used. That’s all there is to it.
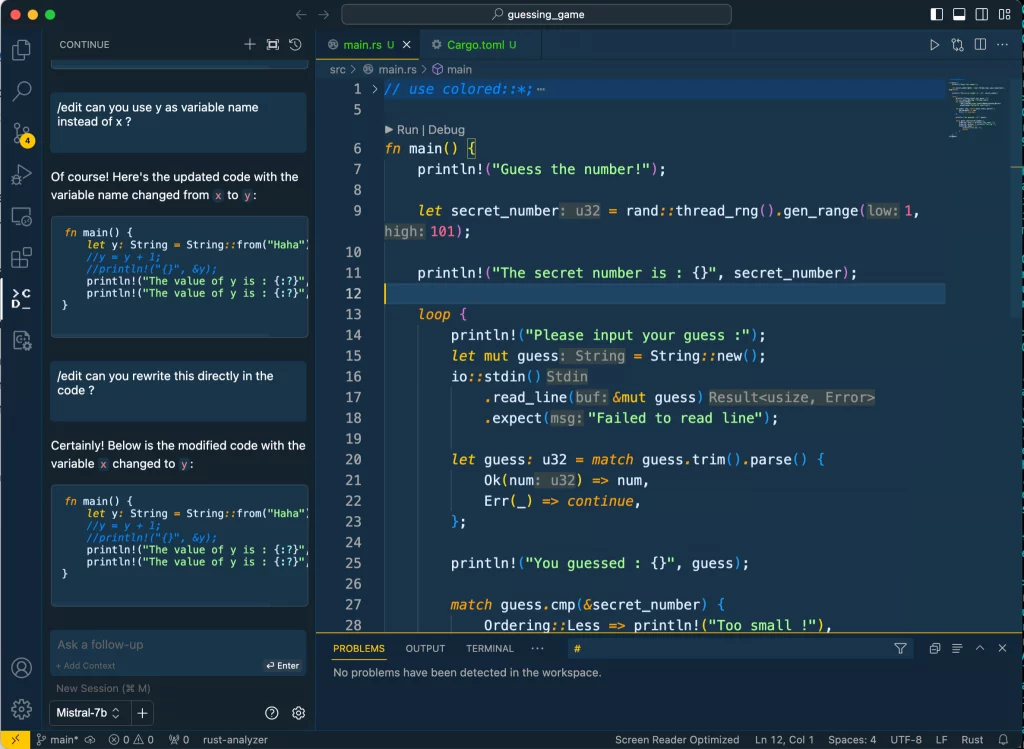
For example, here’s Continue using the Mistral7B template via Ollama on my iMac :
Finally, the third use case is direct access to local models via a computer program. Here too, it’s easy: the applications’ programming interfaces make them easy to integrate into internal IT processes. For example, Ollama offers a REST entry point accessible on port 11434, the documentation for which can be found here. And an ollama-python library has recently been released, making things even simpler.
4. Thoughts
With today’s applications, the use of local models has become very easy. The rapid progress of open-source models makes them a very attractive option, resolving a number of the disadvantages of proprietary models in the cloud. These models do not yet match the performance of the best proprietary models such as GPT-4, but the forthcoming availability of Llama 3 and the rapid progress of Mistral give grounds for optimism.
If local models are operational today, 2024 should see the emergence of smartphone-based models. The Internet is buzzing with rumors that Apple is preparing to launch a new version of Siri based on a generative model that can drive certain phone applications. Samsung, for its part, has developed a language model called Gauss, destined to be integrated into its phones in the near future…
5. References
- What are quantized LLMs ?, by Miguel Carrera Neves Dec. 16th, 2023 on TensorOps : https://www.tensorops.ai/post/what-are-quantized-llms
- Youtube tutorial Ollama : https://youtu.be/MGr1V4LyGFA?si=LE9wmBeVcO0euk3N
- Youtube tutorial LMStudio Youtube byMatthew Berman : https://youtu.be/yBI1nPep72Q?si=x85RpRA9m3ckc8GY
- TutorielYoutube text-generate-webui tutorial by Matthew Berman : https://youtu.be/VPW6mVTTtTc?si=TgkUXx8hX1629fab
- UtilUsing Continue as a VSCode assistant by World Of AI: https://youtu.be/dtfuFeXJ_p8?si=sZftOKiH82s7WZ2G
- Samsung announces ChatGPT rival coming soon to its devices, by Cecily Mauran on MAshable Nov. 8th, 2023 : https://mashable.com/article/samsung-announcement-chatgpt-rival-coming-soon-devices
- Apple unveils Ferret : an open-source Generative AI model that bridges Vision and Language, by Aayush Mittal Dec. 29th, 2023 for Techopedia : https://www.techopedia.com/apple-unveils-ferret-an-open-source-genai-for-vision-language-tasks
Don’t have the resources, technical skills, infrastructure, or time to install, run, and maintain open-source models? MultAI.eu offers access to a wide variety of open-source models, all just one click away. Shoulder to shoulder with proprietary models and with much functionality.
Translated with DeepL and adapted from our partner Arnaud Stevins’ blog (Dec. 25th, 2023).
February 18th, 2024